In this Blog you will find evidence of my journey towards becoming a Data Scientist including the challenges I faced and addressed, Data Science competitions, tools, and tips & tricks. Contact me at @ksocrates or Email me.
Socrates, one of the greatest Greek philosophers of mankind, once said, “The unexamined life is not worth living.” This famous quote can be adapted to Machine Learning models as well. If this quote has to be rewritten to ML world, it will read as “The unexamined ML model is not worth-production.”
An important aspect of the predictive modeling pipeline is, measuring the performance of the model developed. It determines how best the model fits the purpose. The performance of model is measured by running the model on unseen dataset and comparing the output with actual results. There is no one type of metric that can be used to measure the performance of the models. In other words, the techniques used for regression models cannot be applied to classification or clustering models. Let us look at various evaluation metrics used for Linear Regression and how they are important to a business problem.
a. MSE - Means Square Error (L2 Loss)
Mean Squared Error (MSE), also known as Least Squares Error (LSE), is the simple and commonly used evaluation metrics for linear regression. To compute MSE, take the difference between actual and predicted values of each observation, square the differences, and then find out the mean. MSE represents both the variance and bias of the predicted values.
If the outliers represent anomaly that is important for business and should be detected, then we should use MSE. Note that MSE is sensitive to outliers, but it gives a more stable and closed-form solution.
The unit of MSE is square times the unit of the predicted value. The MSE can be calculated using the sklearn library as below:
b. RMSE – Root Mean Squared Error
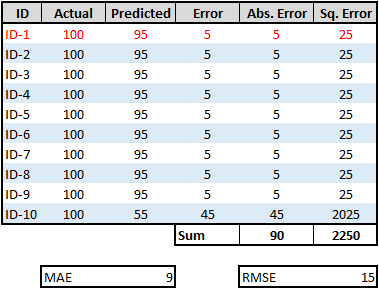
Root Mean Squared Error (RMSE) is the next simplest form of evaluation metrics used for linear regression. To compute RMSE, first, compute MSE as stated above and take a square root of the final value. The square root is taken to arrive at the scale of the error same as the scale of the predicted value. In other words, the unit of RMSE is the same as the unit of the predicted value. As RMSE is the square root of MSE (Variance), it represents the Standard Deviation of the error.
Note that any outliers present in the data will magnify the error term to a higher value.
The RMSE can be calculated using the sklearn library as below:
c. RMSLE - Root Mean Squared Logarithmic Error
The Root Mean Squared Logarithmic Error is calculated by taking the log of actual and predicted values before computing the error. After taking the log values, it is the same as computing the RMSE. RMSLE is used in cases where the predicted values above the actual values (overestimation) are preferable than the predicted values lower than the actuals (underestimation). Further, RMSLE considers only the relative error between the actual and predicted values and not the scale of the error.
The RMSLE can be calculated using the sklearn library as below:
RMSLE is used when both the predicted and actual values are big numbers. It is used if the huge differences between the predicted and actual values are not to be penalized.
d. MAE - Mean Absolute Error (L1 Loss)
Mean Absolute Error (MAE), also known as the Least Absolute Deviation (LAD), is the average of the sum of the absolute difference between actual and predicted values. In other words, calculate the difference between actual and predicted values of each observation, compute their absolute values, sum it up, and then determine the average. MAE function tries to reduce the absolute differences between the actual and predicted values.
If the outliers represent corrupted data, then we should choose MAE as a loss function. Unlike MSE, MAE is insensitive and more robust to outliers.
The MAE can be calculated using the sklearn library as below:
Cross-Validation (CV) is a model evaluation technique to compute the performance of a Machine Learning (ML) model. After building a model, validating it on trained data fetches the residual errors, and one should never use the same data to measure the quality of a model. It is required to validate it against the unseen data to arrive at the actual performance. Following are the three important CV techniques that are widely used in the industry to measure the performance:
1. Hold-out 2. K-Fold 3. Leave-One-Out (LOO)
Let us take a look at each one of them in detail.
1. Hold-out:
In this technique, the given dataset is split into Train and Test datasets in random. Usually, the split ratio varies from 70:30 to 90:10. The model is trained on the train set and validated on the test set. The performance of the model is computed using predicted outcome and actual value of the test dataset.
Hold-out CV is a widely used technique when the dataset is large. The drawback with this technique is the randomness of the data that may lead to overfitting. Think of a scenario where the dataset is small, and after splitting the train set contains people from a particular state/gender, and the test set has different state/gender.
2. K-Fold:
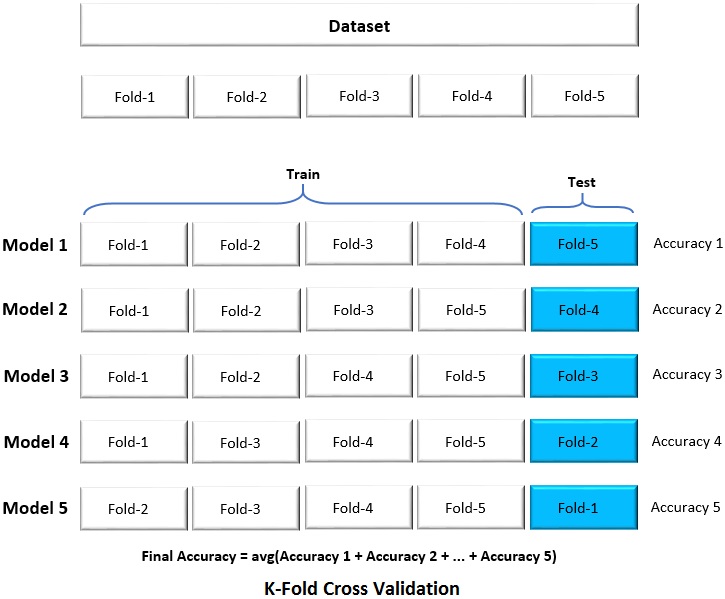
In this technique, the given dataset is split into an equal number (K) of folds. The split may either be Random or be Stratified. The model is iteratively trained on K-1 folds and tested on the fold that is not included for training. Though there is no formula, the number of folds (K fold) varies from 5 to 10 depending on the size of the dataset.
In the above picture, the given dataset is split into 5 folds equally. In the first iteration, folds 1, 2, 3, and 4 are used for training a model (Model 1) and fold 5 is used for prediction. In the second iteration, folds 1, 2, 3, and 5 are used for training (Model 2) and fold 4 is used for prediction. This process is carried out iteratively for all the 5 folds. Based on the predicted values and actual targets of each fold, the accuracy of each model (fold) is computed and averaged for mean accuracy.
In a Random split, as the name implies, the dataset is split in random. The drawback with this approach is, there may be an imbalance in target feature in each fold. In other words, one or more of the folds may have very less or only one target feature than the other folds. Unlike random split, the Stratified split ensures that there is the same amount of distribution of target features in each fold.
The advantage with this technique is that each data point is tested as unseen data and is participated K-1 times in the training process. This technique eliminates the randomness bias stated in the Hold-out method. This method best works for small and medium size datasets.
The main drawback with this approach is that the time taken to train and test the model increases by K-1 times when compared to Hold-out technique. For instance, in 5-fold CV the time taken is at least 4 times higher than the hold-out approach.
3. Leave-One-Out (LOO):
Leave-One-Out is a special case of K-Fold technique in which the K becomes N. The dataset is split into N folds where N is the total number of data points in the dataset. The models are trained N separate times using N-1 data points, and the prediction is made on the left-out data point. This method best works for small size datasets.
The code for K-Fold can be used for LOO as well with below updates:
Conclusion: To increase the accuracy of a model using any of the above CV techniques, fine-tune the hyper-parameters of the model using the grid search. Refer to my article on Hyper-parameter Tuning of Machine Learning Models to know more about it. After arriving at optimal parameters, use them to build a final model using the entire dataset as CV is a technique for Model Checking only and not for Model Building.
One of the widely used techniques to identify all the important features from a given dataset is Backward Elimination, which is discussed in the post How to identify the features that are important for a Machine Learning model?. With this technique, a model has to be developed each time to determine the importance of all the features and eliminate the least important one. As only one feature gets eliminated during each iteration, the model has to be re-trained every time a feature gets eliminated, till all the insignificant features are removed. This technique is, certainly, a computationally intensive and time-consuming. Think of a situation where there are 100s of features and 10s of 1000s of observations in a dataset, and we want to identify the important features.
Permutation Importance or Mean Decrease Accuracy (MDA):
In this technique, a model is generated only once to compute the importance of all the features. Due to this, the Permutation Importance algorithm is much faster than the other techniques and is more reliable.
The following steps are involved, behind the scene:
A model is created with all the features in a dataset (This is the only model created)
The values in a single feature are randomly shuffled, and predictions are made using the resulting dataset
The predicted values are compared with the actual values to compute the performance degradation due to the shuffling (The feature is “important” if shuffling decreases the performance because the model relied on that feature for the prediction)
The feature’s value is unshuffled to bring it to the original state
The steps 2 to 4 are carried out with the next feature in the dataset until the importance of all the features are computed
Random Shuffle of the first feature
Let us take a sample dataset 50-Startups.csv, run a simple Random Forest Regressor model, and compute Permutation Importance.
The above code prints a table with the list of features and weights in descending order, as shown below. The number before the ± denotes how much the model performance decreased with a random shuffling of that particular feature alone. The number after the ± denotes how the performance varied from one reshuffling to the next.
Conclusion:
Based on the above table, the performance of the model got significantly degraded when RDSpend was shuffled, making it the most important one. When the MarketingSpend was shuffled, the performance was degraded to some extent making it the second important one. It is evident that RDSpend and MarketingSpend are the ones that have more influence in determining the Profit of a startup company. Shuffling of the other features have very less impact on performance, and hence they can be eliminated.
Note: It is highly recommended to use the Permutation Importance technique after eliminating the highly correlated features because shuffling of one correlated feature may not find its importance as the model has access to the other similar feature. If all these correlated features are dropped from the dataset based on its least importance, then the final model may have a bad performance if one of the correlated features are highly significant.
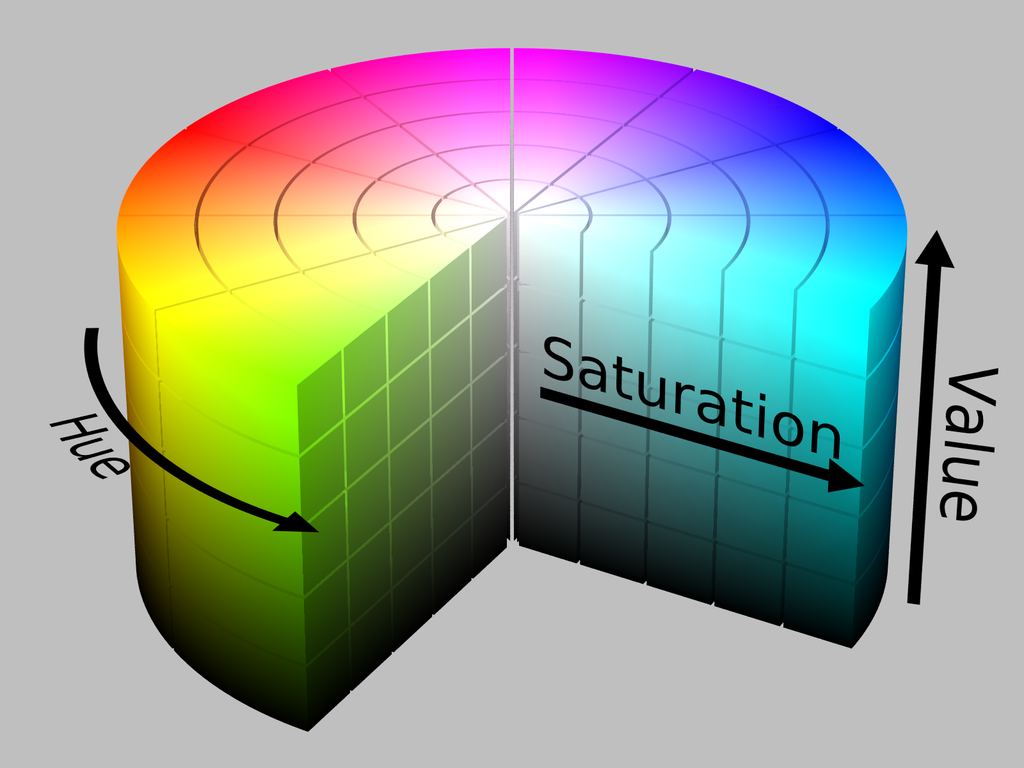
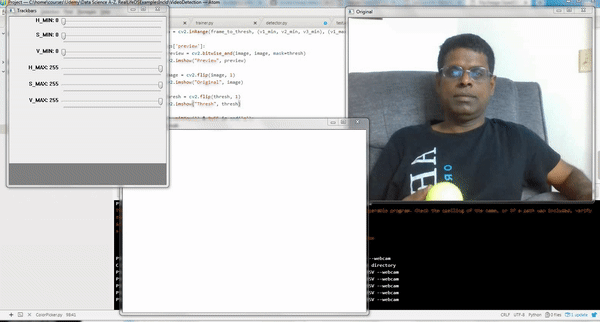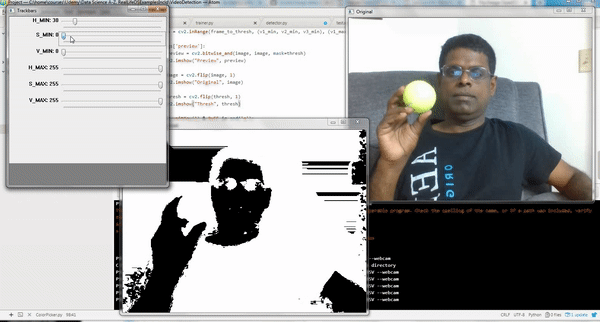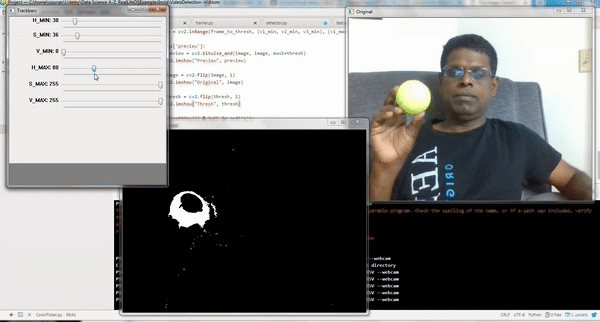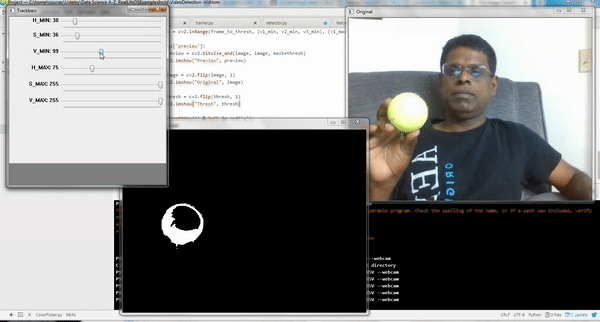
If a Computer Vision (CV) related application deals with detecting or tracking a specific object, then it is necessary to determine the range of HSV (Hue, Saturation, and Value) or RGB (Red, Green, and Blue) values of that object. This range is required to be specified as part of the coding to detect that object. If the correct range is not specified, the CV algorithm may pick-up noises as well, besides the actual object, leading to false detection and tracking.
In the below OpenCV code snippet, a Tennis ball is about to be detected and tracked when it is moved in front of a webcam. To identify the ball alone, not any other objects/ noises, it is necessary to specify a correct range of corresponding HSV numbers.
Refer to the article What is the HSV Color Model? to know more about HSV. Here is the quick look at what HSV is.
The exact HSV or RGB range can be determined programmatically using OpenCV for an object to be identified or tracked. In the below clip, a Tennis ball, which needs to be detected and tracked, is used to determine its HSV range.
Grab the python code ColorPicker.py from my GIT repository, copy the same to a local machine, and issue one of the below commands in Command Line Interface (CLI), based on your requirement. The source code is taken from Adrian Rosebrock’s repository.
To determine HSV range based on an image, python ColorPicker.py --filter HSV --image /path/image.png
To determine RGB range based on an image, python ColorPicker.py --filter RGB --image /path/image.png
To determine HSV range based on webcam video, python ColorPicker.py --filter HSV --webcam
To determine RGB range based on webcam video, python ColorPicker.py --filter RGB --webcam
This script launches three windows as shown in the above clip:
Original: shows original video/image
Trackbars: shows sliders to adjust the HSV/RGB Min and Max range
Thresh: shows video/image adjusted to the selected HSV/RGB range
Adjust the Min and Max slide bars in Trackbars window till you get the desired object alone appear in White in Thresh window. Take the corresponding HSV/RGB range and use them in the code as indicated earlier.
To improve the performance of a machine learning model, one of the aspects that Data Scientists focus on is, tuning and fine-tuning hyper-parameters of Machine Learning (ML) models, besides working on Feature Handling and Model Ensemble. Parameter tuning plays a vital role in achieving higher accuracy of an ML model.
The initial accuracy of XGBoost model, from the above PDF document, is 73.26% with random parameters. After tuning 6 different parameters, the accuracy increased by 1.16% to 74.42%. Though the increase in accuracy is marginal due to the very small dataset, this document explains how one can tune hyper-parameters using GridSearchCV and improve the performance.
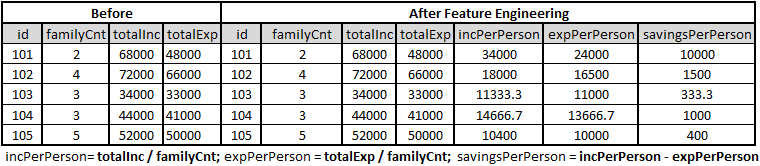
To improve the performance of a Machine Learning (ML) model, Feature Engineering, Feature Extraction, and Feature Selection are the important aspects, besides Model Ensembling and Parameter Tuning. Data Scientists spend most of their time working on features than on developing ML models. This post, which contains examples and corresponding Python code, is aimed towards reducing the time spent on handling features.
Feature Engineering is more of an art than science that requires domain expertise. It is a process through which new features are created, though the original dataset could have been used as such. The new features help arrive at better ML model than the one trained from the original dataset. Most of the time, the new features help improve the accuracy of a model and help minimize the cost function.
In Feature Extraction, the existing features are converted and/or transformed from raw form to most useful ones so that the ML algorithm can handle them in a better way. Let us dive into some of the frequently used feature engineering techniques that are widely adopted across the industry on the Categorical features.
A. Categorical Features:
One-hot Encoding: Represent each categorical variable as a binary vector
Label Encoding: Assign each categorical variable (label) a unique numerical ID
Label Count Encoding: Replace categorical variables (labels) with their total count
Label Rank Encoding: Rank categorical variables (labels) by their count (more count higher number)
Target Encoding: Encode categorical variables by their ratio of target (label)
NaN Encoding: Assign explicit encoding to NaN values in a category
Expansion Encoding: Create multiple categorical variables from a single variable
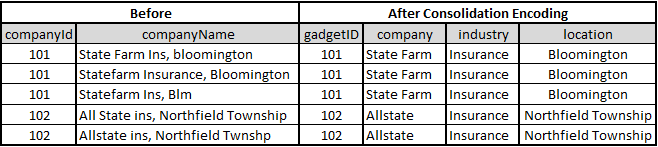
Consolidation Encoding: Map different categorical variables to the same variable
Performing feature engineering on numerical data is different from that on categorical data. In numerical data, the techniques involve rounding, binning, scaling, missing values imputation, the interaction between features, etc.
Feature Selection helps identify the most significant features, from a given dataset, which will be helpful in generating a better model. Besides the raw dataset, a Data Scientist has to use the engineered and extracted datasets as well to identify the importance of them. For example, to predict whether a startup company will be profitable or not, the Administrative expense may not be a significant feature when compared to Marketing and R&D expenses. To determine this, follow the article “How to identify the features that are important for a Machine Learning model?” that explains how features can be selected using statistically and through the ML model.
Human vision is one of the most complex functions of the brain. Computer Vision(CV), a sub-discipline of Artificial Intelligence (AI) attempts to replicate some visual functions of the brain, one of them being able to recognize faces. The first step is to detect the face. In this demo video feed, I used the OpenCV library to detect the face and eyes of myself and pictures behind me.
Face detection in video has a wide range of applications. For example, in video surveillance, you can use automatic face detection to detect if someone just came into the view of the camera and send out an alert, instead of having a person constantly looking at the video for human activity.
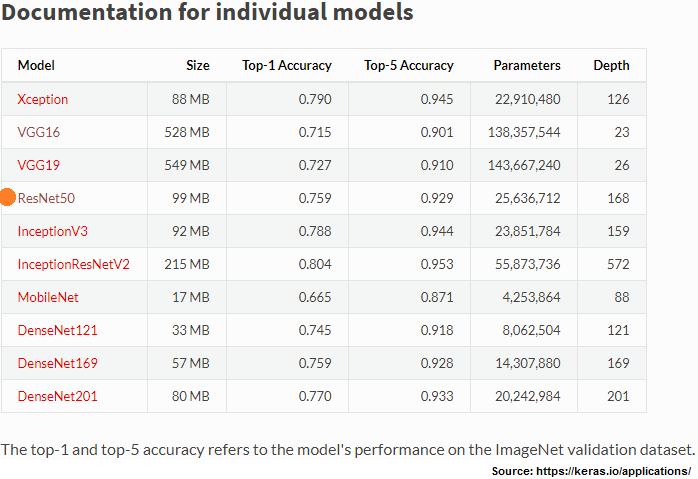
In one of my earlier posts, I explained about How to build a Web App for a Machine Learning model using Flask micro framework? In this post, I am sharing a full-fledged interactive web application, developed using a pre-trained, deep learning, neural network model - ResNet50, which is trained on ImageNet dataset and bundled with Keras library. The below table lists all the pre-trained models bundled with Keras library. Any of these libraries can be used to build an application instantly:
I used Heroku - A cloud-based, Platform as a Service (PaaS) provider that enables developers to build, run, and operate applications instantly. The code base used to develop this app can be found in my GitHub location.
If you would like to know the step-by-step details of how to create an app, load the files from GitHub, build, and deploy the app in Heroku, leave a note in the Comments section, by clicking this post, and I will get back to you as soon as possible.
In one of the recent meet-ups, I was asked, which is important for generating a good Machine Learning (ML) model - A good Data Scientist or Data? That is an interesting question, right?
A data scientist can be hired, trained, or outsourced by any enterprise at any time, but how about the data? The data can only be captured and collected by that enterprise alone, through their core business processes, over a period of time. Data collection takes time; it requires infrastructure and software components to be in place. Of course, external sources, either publically available or third party data, can be leveraged as supplemental sources for improving the machine learning model efficiency but the core secret sauce i.e. data has to come from the enterprise itself.
The next challenge is to identify whether the data captured is good or bad. In other words, are all the captured features important for the generation of a good machine learning model? A good domain knowledge may help answer this question partially, but how to identify and prove it mathematically? Well, this challenge can be approached either using Statistical methods or using Machine Learning models itself.
Statistical Method:
In this method, we do not create an actual machine learning model using any algorithms but we use the given dataset to analyze how the features are correlated to each other. Chi-squared and Adjusted R-squared are the two majorly used metrics that can be employed. Though there are many methods viz All-in, Backward Elimination, Forward Selection, Bi-directional Elimination, and Score Comparison, Backward Elimination (a stepwise-regression technique) is the widely used method in the industry.
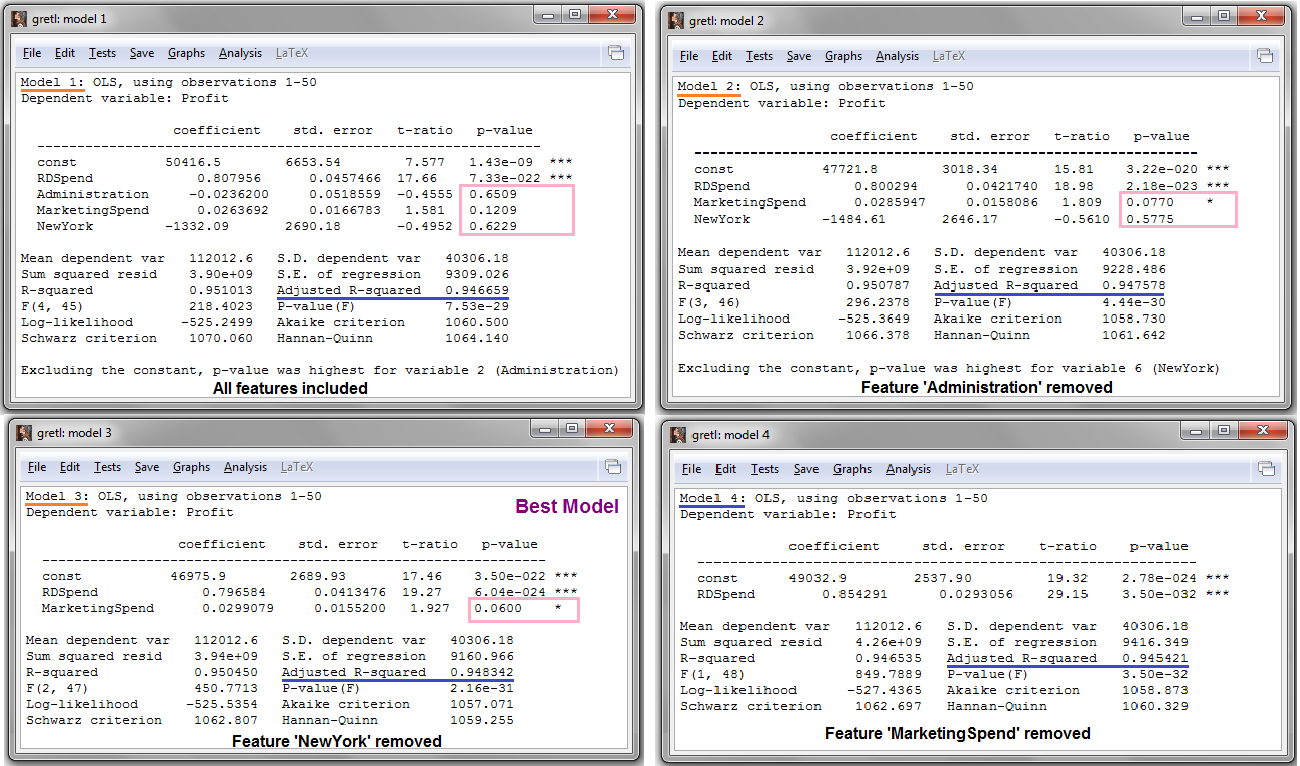
This can be achieved using Gretl - an open-source statistical software package provided by SourceForge. Gretl User Guide is a good resource to start with for this exercise. Follow the below steps to perform backward elimination:
Select a significance level (SL) (say, 0.05)
Fit a model using Gretl with all available features (predictors). The dataset (50-Startups.csv) used for this analysis can be found here
Identify the feature with the highest P-value
If the P-value of a feature is higher than SL, remove that feature and refit the model with remaining features
Note: Even if there are multiple features whose P-values are higher than the selected SL, remove only the one that has the highest P-value and fit the model again. This is because the removal of one feature will impact the constants, coefficients, and P-value of other features. Further, as we selected an arbitrary value for SL (as 0.05), it is necessary to compare the models before and after removing the selected feature for Adjusted R-squared metric (or Chi-squared) as well.
Do the steps 3 and 4 to a point where the selected features yield highest Adjusted R-squared values and/or the P-value of features is less than the selected SL. After reaching that point, the list of features collected are the ones that are important for building a good machine learning model
In the above picture, Model 4 contains all the features whose P-value are less than 0.05. However, its Adjusted R-squared value is less than that of Model 3 that contains a feature that has P-value greater than chosen SL (0.06 > 0.05). In spite of this feature, Model 3 (thereby the features in it) has to be selected as the best one based on its highest Adjusted R-squared value. From Model 3, the important features that required for generating a machine learning model, which can predict the target feature, are RDSpend and MarketingSpend.
Machine Learning Model:
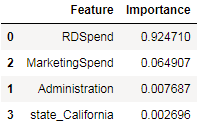
In this method, we create an actual machine learning model using one of the algorithms that output importance matrix as part of the model generation. This matrix will provide details about each feature in a dataset and its percentage of importance in generating the model
Let us take a simple Random Forest Regressor model to arrive at the important features using the same dataset (50-Startups.csv) we used for the statistical method.
The above code prints a table with the percentage of importance of each feature in descending order, as shown below. This clearly indicates that RDSpend and MarketingSpend are the two features that are majorly important for generating a model that can predict the target feature.
Conclusion:
From both Statistical and Machine Learning methods, it is evident that RDSpend and MarketingSpend features are the ones that are required to determine the Profit of a startup company. The other features are not significant enough to be included in a model and hence they can be rejected.
Further, these selected features can be used as a feedback mechanism to business processes that capture data or to the process that aggregates data from different data stores for model generation. This will drastically reduce the number of features that need to be captured for model generation and during real-time prediction.
To realize the true benefit of a Machine Learning model it has to be deployed onto a production environment and should start predicting outcomes for a business problem. Most Data Scientists know how to extract data from multiple data sources, combine, clean, and consolidate data, perform feature engineering, extract features, train multiple models, ensemble, validate, and test the models. But what they lack is how to take a trained model onto production.
There are multiple ways to deploy a model in production. However, in this post, we will go through the step-by-step process of creating a basic model and deploy it as a Web App using Flask micro framework - a Python based toolkit. These steps are executed in Windows Operating System. But for Linux, Ubuntu, and other OS, this should work seamlessly by adopting relevant syntax.
Steps:
Let us build a simple Machine Learning Model using iris dataset that is bundled with sklearn package. This can be done using Jupyter Notebook, PyCharm, PyTorch or any other IDE that you are comfortable with.
Now that your machine learning model is created and persisted in hard-disk as SVMModel.pckl
In Windows Command prompt, execute the below command to install Flask framework and its associated dependencies/libraries:
pip install flask gevent requests pillow
Let us create a folder structure as below so that it can be extended to production-like interactive and real-time application later.
Root folder flask-blog contains server start-up class
Sub-folder static contains image, CSS, and JavaScript files
Sub-folder templates contains static and dynamic html files
Under flask-blog folder, create a file called server.py with below content:
After the above file is created, go to flask-blog folder, open a Command prompt, and run the command python server.py. It will execute as below:
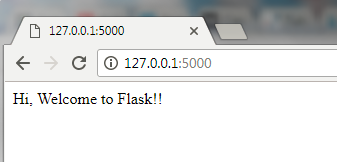
After the server is started successfully, open a browser window, and enter URL http://127.0.0.1:5000/
If you get a message Hi, Welcome to Flask!! in your browser, congratulations, your Flask server is up and running successfully! If you get any error or could not get the server up and running, leave a note under the Comments section of this blog and I will get back to you as early as possible.
Having successfully started the server, let us move on to extend server.py to predict the new observation using previously trained and stored SVM Model.
Before updating code, go to the Command prompt and stop Flask server using Ctrl-C. Update server.py code as below, or you may simply copy & paste the contents to your code.
Go to the Command prompt again and start the server using python server.py.
Once the server is started, open a browser window and enter the URL: http://127.0.0.1:5000/predict?sepal_length=6.0&sepal_width=2.5&petal_length=5.5&petal_width=1.6
Voila! The predicted class of Iris will appear on the screen as above. Play around by changing the values of features in the URL query string.
Now that you understand how a machine learning model can be created, persisted onto a disk, loaded from disk, can extract features from a browser request, and can use the model to predict the class using those features.
This application can be extended with fancy UI containing form element, dropdown boxes, submit button, etc..
Most of the MOOCs, online courses, tutorials, and webinars talk about how to generate better, robust, efficient, and generic models to address business problems but not the deterioration models over a period of time and how to upkeep them so that it continues to deliver its purpose. Besides Analyzing and Generating models, a Data Scientist’s role extends to Assess and Maintain them after deployment into production.
There are many reasons a model may deteriorate over a period of time. A model may start deteriorating slowly in 3 or 6 or 12 or 18 months depending upon the factors and business problem it addresses. Since there is no fixed period or template to follow, it is highly recommended to assess the model once in 3 months or at least once in 6 months.
Why do models deteriorate?
Consider that there is a model developed to segment customers of an Insurance company. This model may deteriorate due to one or more reasons stated below:
a. Added factors that are not considered originally:
The company expanded its operation to another country or added one or more product lines
b. Changes in Customer Behavior:
Customers (especially millennials) expect instant insurance quotes rather than quotes emailed to them
c. Changes in Business Process:
The company moved from Agent-based system to online system
d. Changes in Existing factors:
The minimum wage of customers got changed but the salary of the model remains same
e. Competitor:
Other competitors offer more products or process claims at faster rate that are not accounted in the model
f. Changes in Industry:
Mergers and acquisition of similar companies in the industry. New start-ups that process quotes and claims through AI
g. Changes in Regulations:
New and/or updated Government regulations. Ex: mandating AML/KYC for baby-boomers and Gen-X customers
h. Changes in Product:
Change in premium rate or coverage of insurance products that makes customers to change their coverage plan
i. Changes in Dataset that are not considered originally:
Change in discount code and/or addition of new discount code for Insurance premium calculation
How to maintain models?
The following Hierarchical Processes shall be employed to maintain a model:
1. Assess: Assess the models periodically and proactively with new datasets and compare its performance with measures. Even if the performance deteriorates but still within the acceptable threshold, it should still be OK. However, this assessment has to be carried out at least once in 6 months.
2. Retrain: If the above assessment falls below the threshold, retrain the model with fresh sample of datasets - sometimes with more number of observations. However, during retraining, keep all the original and derived features of the original model. The fresh and added datasets may lead to change in coefficients of the model performing better.
3. Rebuild: In spite of retrain, if the performance of model does not improve, just scrap the original model entirely and start from scratch. This means, analyzing new and old features, imputing missing values, one-hot encoding and label encoding features, performing feature engineering, building diversified models, and ensemble them. Finally deploy this model into production and perform A/B testing (aka Champion-Challenger testing) to measure the performance of new model.
I was working on a binary Classification challenge for which I had to compute the Performance metrics for all the Predictive models. Using XGBoost, H2O, GBM, and MLR packages, I developed 5 models for which AUC (ROCR) has to be computed.
Following is the order in which the libraries were loaded in the script:
For one of the models (GLMNet), I used the below code to predict Target feature: glmNetPred <- predict(glmNetModel$glmnet.fit, ...)
After prediction, I ran the below code to compute ROCR prediction, and it got executed successfully: ROCRpred <- prediction(glmNetPred, testSetActual)
But when I executed the below code to compute Area Under Curve (AUC), AUC <- as.numeric(performance(ROCRpred, "auc")@y.values)
it gave me the following error:
Error in performance(ROCRpred, “auc”) :
Assertion on ‘pred’ failed: Must have class ‘Prediction’, but has class ‘prediction’.
Now what? I searched for help in Net for any solution but did not find any. When I did more analysis, I found that the ROCRpred object was created using ROCR package’s prediction function, and supplied to performance function of mlr package. But the mlr package expects the object to be of type Prediction.
A careful scan on the logs, when the packages were loaded, also proved the same:
> library(mlr)
Attaching package: ‘mlr’
The following object is masked from 'package:ROCR':
performance
What it means is that both mlr and ROCR packages contain performance function which is identical but have different signatures. The performance function in mlr package expects the parameter to be of type Prediction whereas the same function in ROCR package expects it to be of type prediction and hence is the error!!
There are two ways to solve this issue:
a. Supply package name explicitly while calling the function. With this approach the package name has to be specified in each and every model files and it may reduce the code readability. Further, there are chances of missing it out in some places leading to undesired results.
Since I sourced the libraries at only one place in my script for all the models, the second approach was easier for me, with which I need not specify the package name all over.
So, is it really important to load the libraries in particular order in R? Though it seems to be not in some cases, Yes, they are important in other cases!
Want to learn how to develop a googleVis Motion Chart and upload it in your blog or website, using R? I downloaded the Bikesharing dataset from Kaggle’s Competition site, performed some data munging and grouping, and prepared a googleVis Motion Chart. In X-axis, choose ‘Time’ variable instead of default ‘Period’ to match with the slider below. You may slowdown the animation by dragging arrow down the arrow as indicated here.
Note: This chart will not be visible in some of the mobile devices due to Flash incompatibility. Please use your regular computer to see this chart.
The R code for this chart can be found in my Github repo.
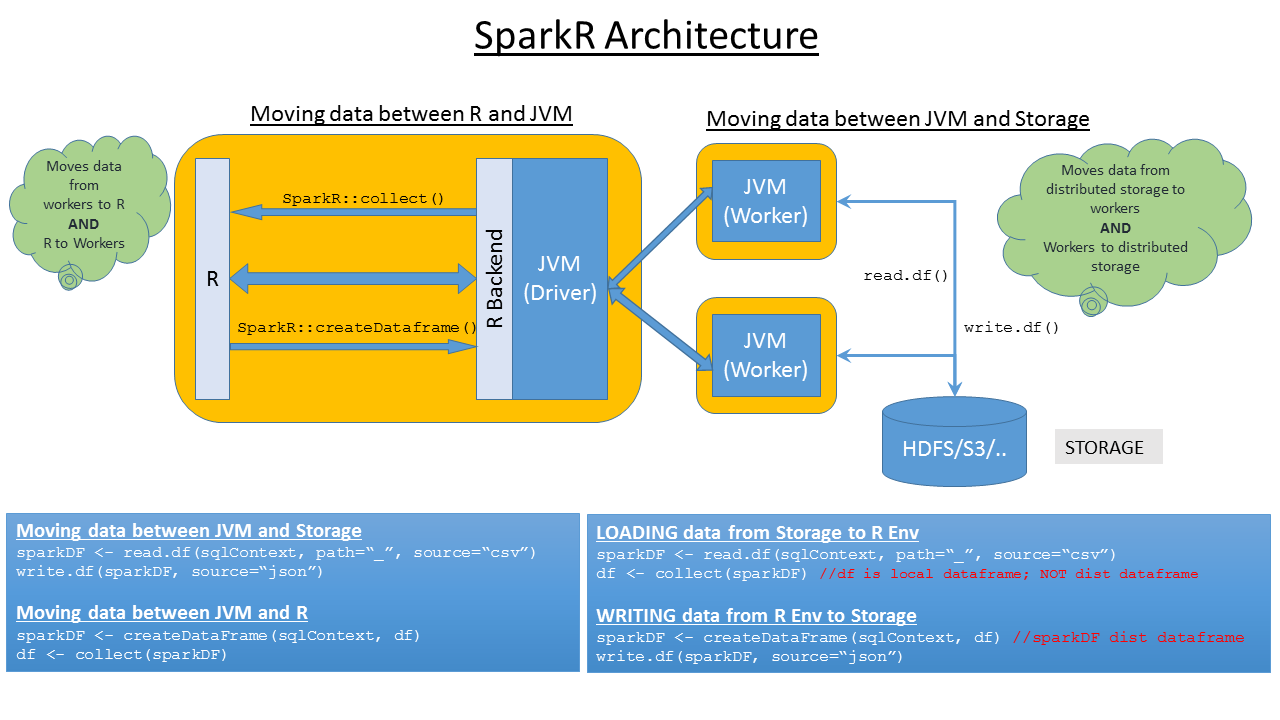
Before learning any tools and technologies, it would be beneficial if we could understand the underlying architecture of them. The below visual represents my understanding of SparkR package provided by Apache to handle Big Data in Data Science field. Though the MLlib in SparkR has limited number algorithms, adoption of new algorithms are taking place at faster rate.
This is my another attempt to prepare an interactive histogram using Shiny Apps. I have embedded both Server and UI side codes that produced this app on the main page itself. Take a look at it here or directly below:
Most of us know that R Programming has good prediction algorithms and rich visual representation libraries available. I was wondering whether we can build an interactive Web application using R and host is online. Shiny library, a Web Application Framework for R, came-in handy for me to achieve this. Using Shiny, developed a very simple interactive web application to predict the mileage of a car based on User’s Manual. To predict that, I had to develop a Linear Regression model based on mtcars dataset provided by ‘Motor Trends Magazine’ for various Cars, Makes, and Models, and finally hosted the application using Shinyapps. To determine the mileage of your car, feel free to use this interactive Shiny application hosted in my Shiny site or directly below.
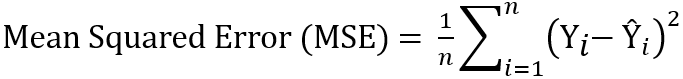
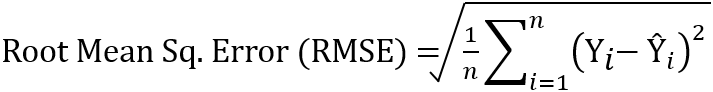
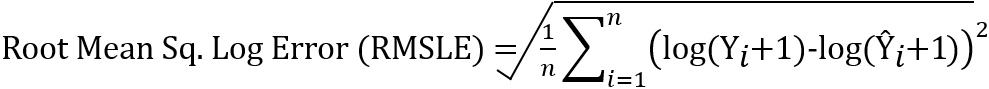
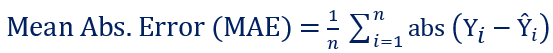


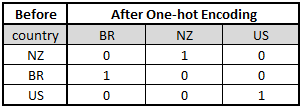
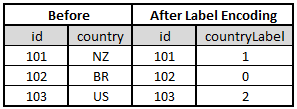
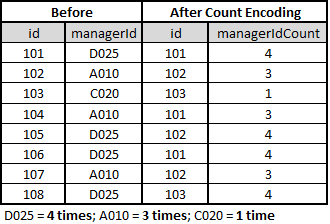
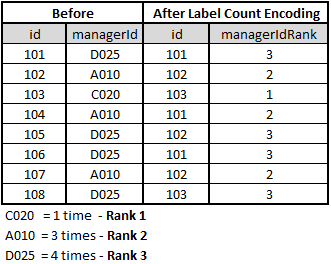
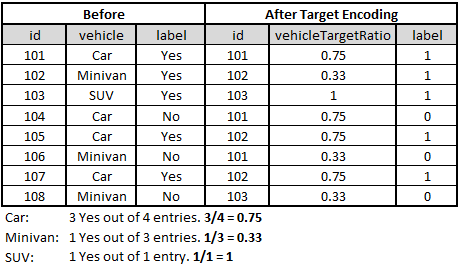
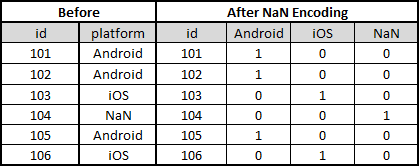
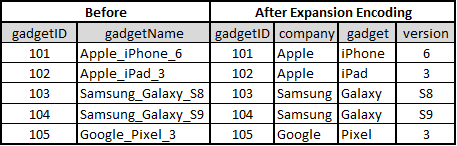
 There are no fixed ways to perform consolidation encoding. It purely depends on the type of data provided. However,
There are no fixed ways to perform consolidation encoding. It purely depends on the type of data provided. However, 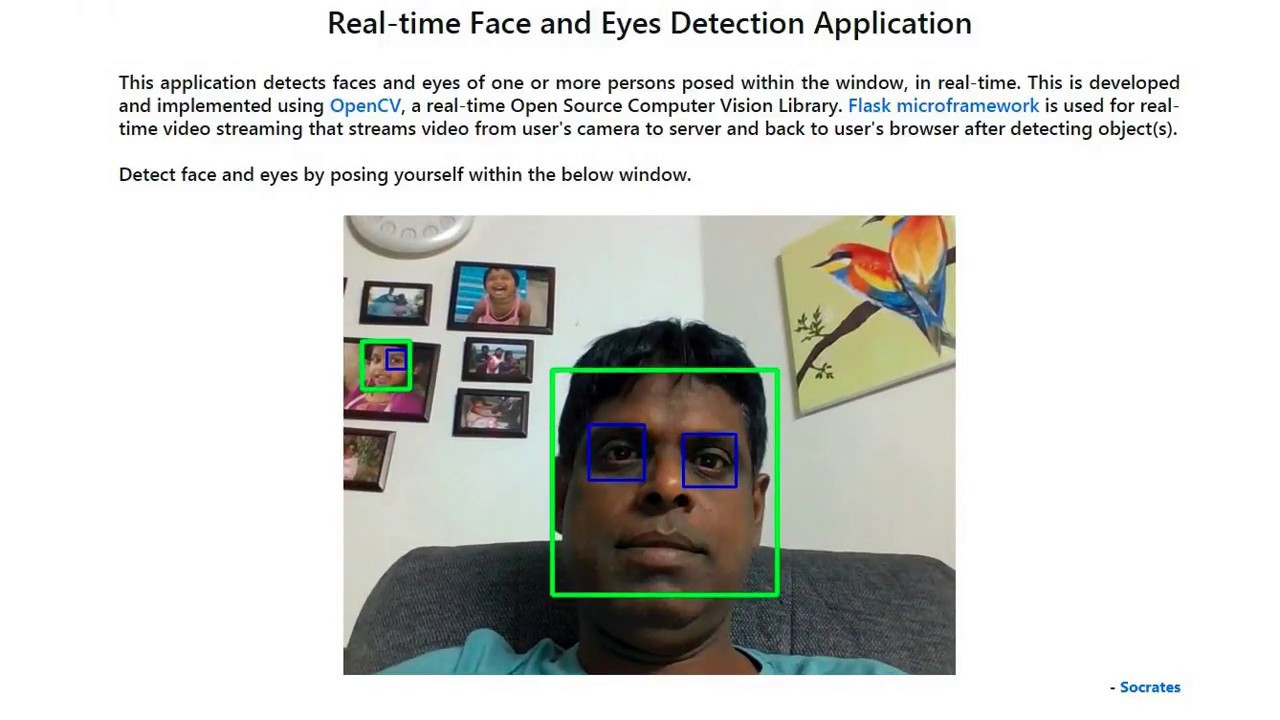
 If you get a message Hi, Welcome to Flask!! in your browser, congratulations, your Flask server is up and running successfully! If you get any error or could not get the server up and running, leave a note under the Comments section of this blog and I will get back to you as early as possible.
If you get a message Hi, Welcome to Flask!! in your browser, congratulations, your Flask server is up and running successfully! If you get any error or could not get the server up and running, leave a note under the Comments section of this blog and I will get back to you as early as possible.