Feature Engineering, Feature Extraction, and Feature Selection
To improve the performance of a Machine Learning (ML) model, Feature Engineering, Feature Extraction, and Feature Selection are the important aspects, besides Model Ensembling and Parameter Tuning. Data Scientists spend most of their time working on features than on developing ML models. This post, which contains examples and corresponding Python code, is aimed towards reducing the time spent on handling features.
Feature Engineering is more of an art than science that requires domain expertise. It is a process through which new features are created, though the original dataset could have been used as such. The new features help arrive at better ML model than the one trained from the original dataset. Most of the time, the new features help improve the accuracy of a model and help minimize the cost function.
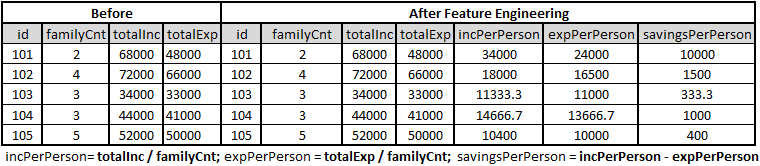
In Feature Extraction, the existing features are converted and/or transformed from raw form to most useful ones so that the ML algorithm can handle them in a better way. Let us dive into some of the frequently used feature engineering techniques that are widely adopted across the industry on the Categorical features.
A. Categorical Features:
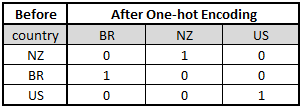
- One-hot Encoding: Represent each categorical variable as a binary vector
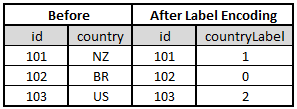
- Label Encoding: Assign each categorical variable (label) a unique numerical ID
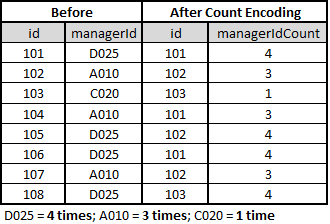
- Label Count Encoding: Replace categorical variables (labels) with their total count
- Label Rank Encoding: Rank categorical variables (labels) by their count (more count higher number)
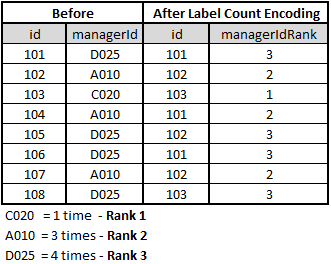
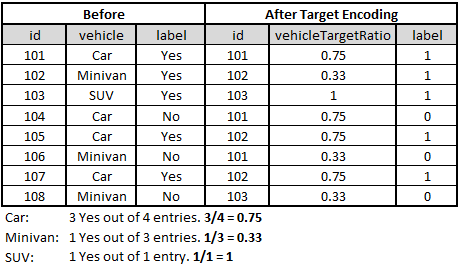
- Target Encoding: Encode categorical variables by their ratio of target (label)
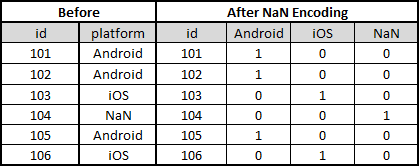
- NaN Encoding: Assign explicit encoding to NaN values in a category
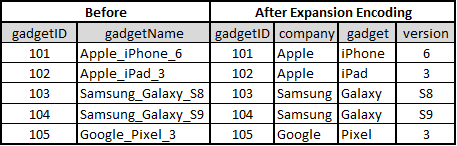
- Expansion Encoding: Create multiple categorical variables from a single variable
- Consolidation Encoding: Map different categorical variables to the same variable
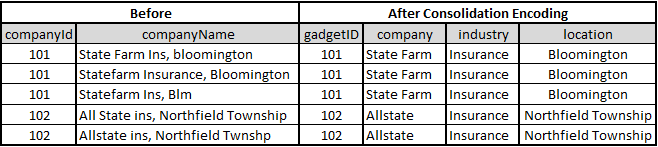 There are no fixed ways to perform consolidation encoding. It purely depends on the type of data provided. However, Regular Expressions (regex), String parsing, Stemming, Lemmatisation, Stop words and other techniques used for Natural Language Processing (NLP) can be employed to consolidate the data.
There are no fixed ways to perform consolidation encoding. It purely depends on the type of data provided. However, Regular Expressions (regex), String parsing, Stemming, Lemmatisation, Stop words and other techniques used for Natural Language Processing (NLP) can be employed to consolidate the data.
B. Numerical Features:
Performing feature engineering on numerical data is different from that on categorical data. In numerical data, the techniques involve rounding, binning, scaling, missing values imputation, the interaction between features, etc.
Feature Selection helps identify the most significant features, from a given dataset, which will be helpful in generating a better model. Besides the raw dataset, a Data Scientist has to use the engineered and extracted datasets as well to identify the importance of them. For example, to predict whether a startup company will be profitable or not, the Administrative expense may not be a significant feature when compared to Marketing and R&D expenses. To determine this, follow the article “How to identify the features that are important for a Machine Learning model?” that explains how features can be selected using statistically and through the ML model.