Allstate Insurance Company - Prediction of Severity of Insurance Claims
13 Dec 2016This time Allstate Insurance Company sponsored a “recruitment” competition in Kaggle to predict the cost of insurance Claims so that the severity of a Claim can be determined in an automated way. The determination of Claims severity will improve Claim Service that Allstate provides to its customers, which in turn will improve the Customer Experience for the 16 million households it protects today.
The competition ran from 10-Oct-2016 to 12-Dec-2016 and there were 3055 individuals who participated across the globe.
The dataset comprised of 116 categorical and 14 continuous features. The “loss” feature given in the train dataset is the one that had to be predicted from the test dataset. Mean Absolute Error (MAE) - measure of how close the predicted values are to the eventual outcomes or actuals, was used to evaluate and score the loss prediction. Refer to any of my code files in Github - Allstate folder for its implementation.
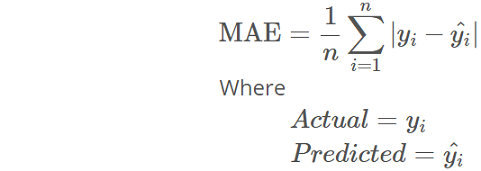
To test my submission file and to know where I stand in Public Leaderboard, I prepared a quick and dirty XGBoost Model with basic and default parameters. After that I built the following set of models to ensemble:
- Generalized Boosted Regression Model (GBM) with Out-of-Bag (OOB) estimator, Gaussian distribution, and 5-fold cross-validation
- 5 H2O Deep Learning Models each with 2 levels of hidden layers, 20 epochs, Huber distribution, and Rectifier activation
- 10 folds of MXNet Deep Learning Models each with 2 levels of hidden layers and one-hot encoding
- ExtraTrees Model with one-hot encoding and 3 random cuts for each feature
- XGBoost Model with parameter tuning and feature engineering
After creating the above models, I took arithmetic mean of all the predictions. Then I ensembled by applying different weightage to each model’s predictions, cross-validated, and then submitted. Finally, at the end of the competition, I could get into top 20% (604 out of 3055) in Private Leaderboard.
Refer below for first few rows of submission file:
| id | loss |
|---|---|
| 4 | 1626.451 |
| 6 | 2034.433 |
| 9 | 10186.82 |
| 12 | 6364.859 |
| 15 | 838.1675 |
| 17 | 2330.886 |
| 21 | 2103.839 |
| 28 | 902.1843 |
| 32 | 2544.185 |
| 43 | 3245.454 |
One of the key challenges with this competition was the size of the data, after feature engineering and one-hot encoding. In order to process the data and generate the models, I used the Domino Data Lab’s computing platform. For most of the above models, I chose Medium Hardware Tier (4 core. 16GB RAM) costing around $40.
